Largest by volume is for coding. I use Claude code, but I don’t use it with Anthropic’s LLMs as it is too expensive, though I acknowledge they are the best. Though GLM-5 is narrowing the gap substantially.
I use GLM-5 by z.ai. It’s good enough for what I do and has much higher limits than Claude’s coding plans (where after a few prompts you can run out and end up having to sign up for $100/$200 plans - I know people who sign up to multiple $200 claude plans as the allowance is so low).
I previously gave a discounted sign-up link for z.ai, but I’m not sure you can even sign-up any more, they were so in demand that they stopped taking new sign-ups so I was glad I got the Pro plan while it was still available with the discount link and with the special 50% Christmas discount stacked on top.
I’ve also used Qwen Code CLI and Google’s version. Qwen had very generous free tier, but I actually preferred GLM to both Qwen and Gemini.
I also run my own LLMs on local hardware for availability and speed. I run HY-MT for translation and Qwen3 for general tasks. I also run my own TTS and STT models for transcribing text and also converting text to audio so I can listen to stuff when on the go.
I used to use Gemini 3 Pro a lot but they really heavily curtailed the free tier. I also use ChatGPT which still has a generous free tier. Of course, for your use case, you will pay to avoid privacy leaks.
The new Minimax is also making waves, but I haven’t tried that. That is just small enough that you could buy hardware to run it locally.
The Chinese AI labs released a lot just now before Chinese new year, so we have the new GLM-5, MimiMax M2.5, Qwen3.5 and soon Deepseek should release too. So we have very good open source offerings. Anthropic just released a new version of Sonnet too.
We’ve been spoiled, there are a lot of open source models of all sizes to suit hardware from powerful GPU clusters down to CPU only inferencing.
In terms of coding subscription, I’m quite a light user. I don’t use it every day and only use it sporadically (I know people who literally schedule their sleep around the 5 hour window and strategically trigger windows at optimal times to maximize usage).
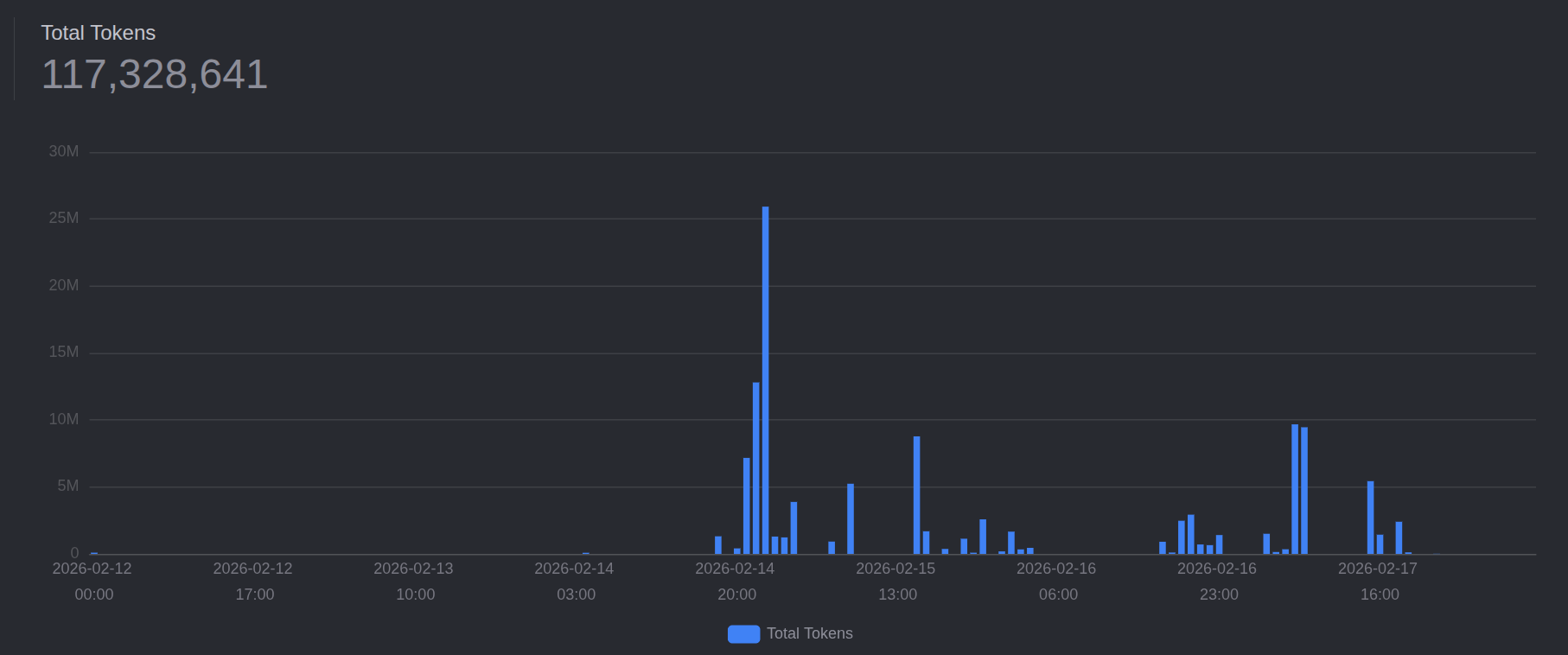
Even still, I burned through 117 million tokens in the last 7 days and 3 of those days didn’t have usage at all. Lord only knows how much that would have cost if I paid API costs directly…
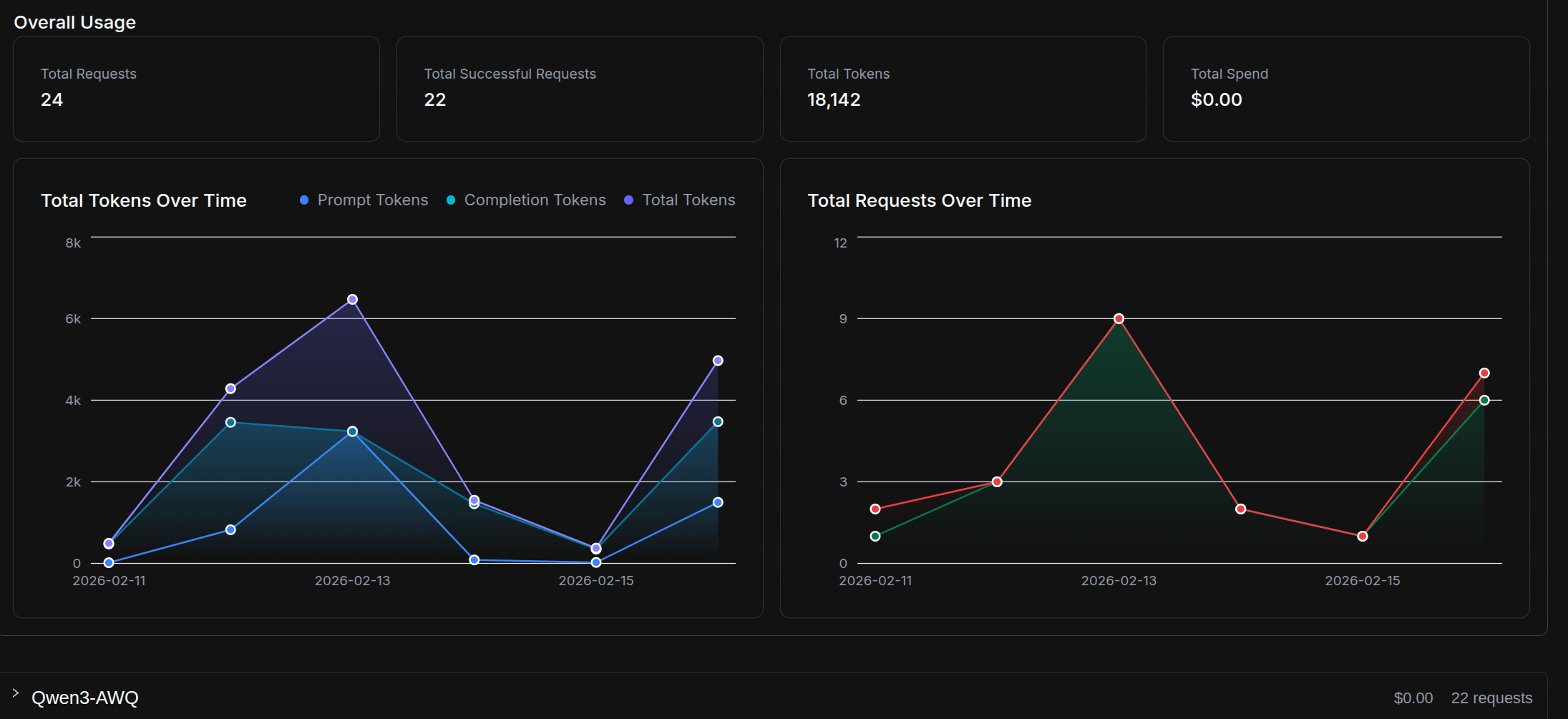
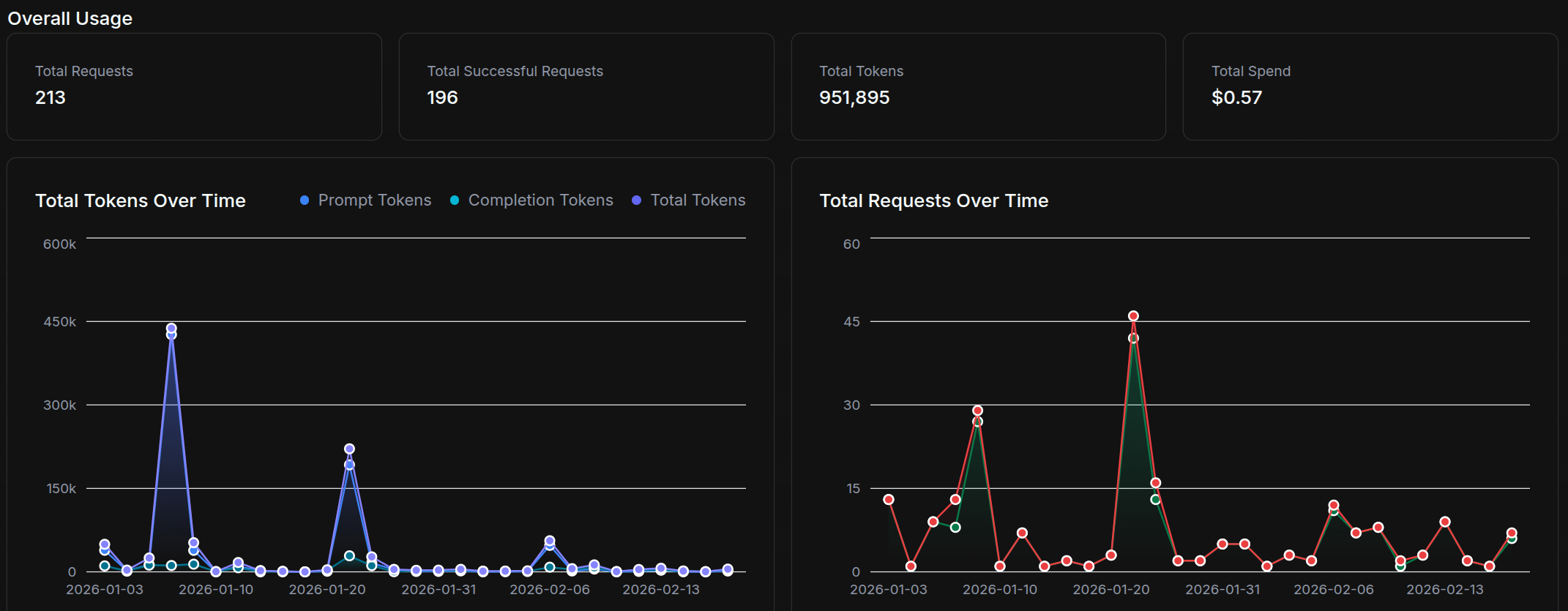
Checking my internal Qwen3 usage, I have only 18k tokens in the last week and about a million since the start of the year. I tend to use only my local model when I’m out of free tier on both ChatGPT and Gemini or if I need fast guaranteed responses: