@nugget
I posted a parser for postfinance ( The beans manual ) , works perfect with beancount ![]()
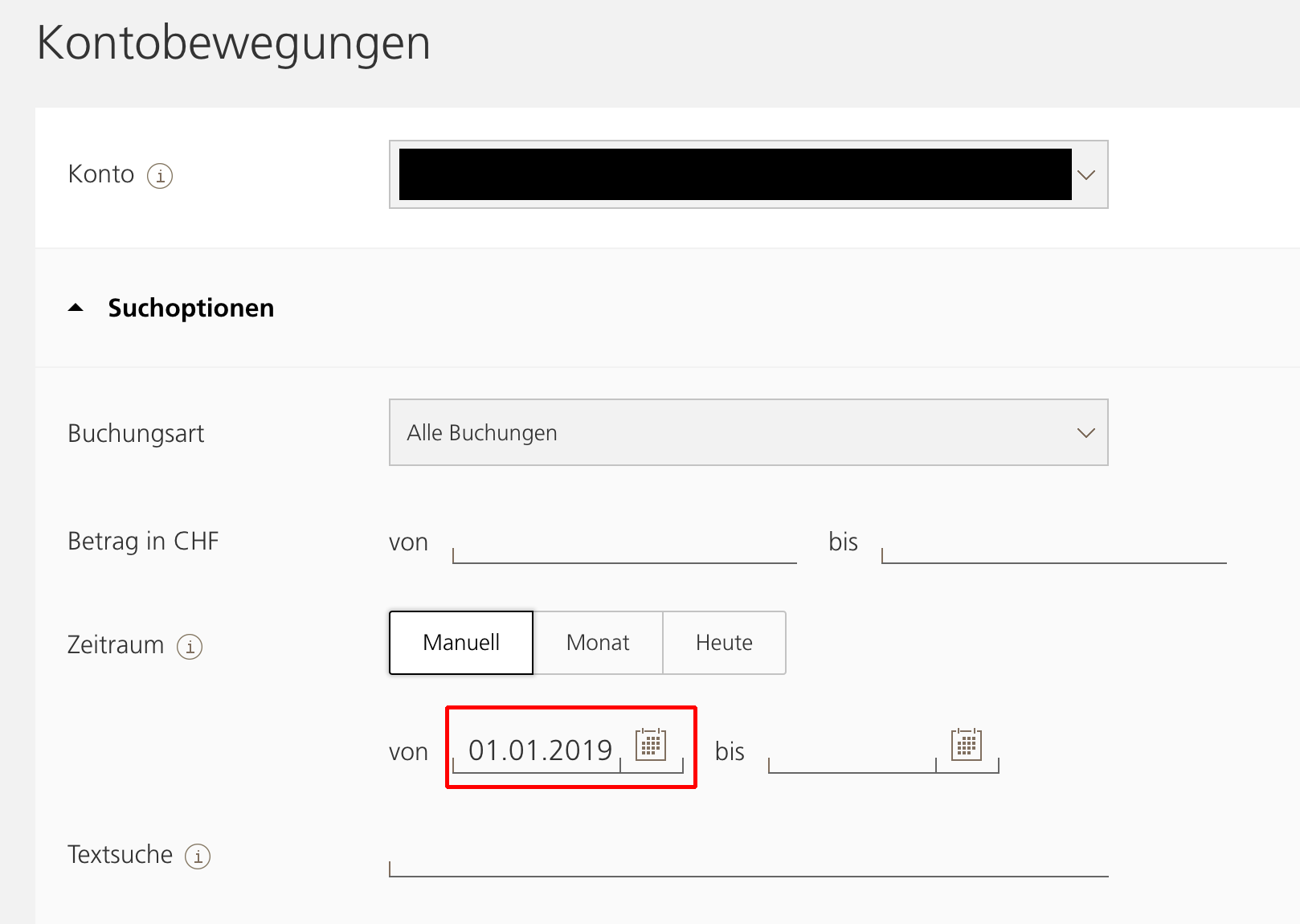
With the csv you can parse it and use it with beancount.
You can edit the “examples.rules” for the matching:
…
description =~ “Mintos Marketplace” → Assets:DE:Mintos:Investments
description =~ “Wohnungsmiete.*” → Expenses:Home:Rent
…
And parse your csv file with beans:
./beans import -i ch.postfinance -c example.rules -a Assets:CH:Postfinance:Shared postfinance20191102.csv >> myfile.beans